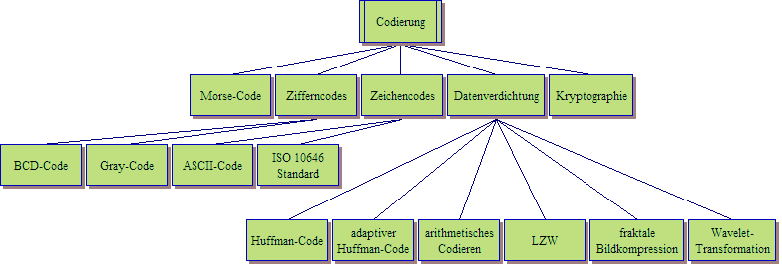
Codierung
Am Schluss der Seite befinden sich Aufgaben und Exkurse.
Begriffe
| Nachricht: | Mitteilung | |
| Information: | Bedeutungsgehalt einer Nachricht
|
|
| Alphabet: | Einfachstes Alphabet: binäre Stellen - womit pro Stelle zwei Werte möglich sind, zum Beispiel 0 oder 1. Jede Stelle entspricht hier einer Informationsmenge von 1 Bit. Die Zeichen eines deutschen Textes können 26 unterschiedliche Werte (26 Buchstaben) annehmen. |
|
| Codierung: | Abbildung einer Nachricht auf Symbole, zum Beispiel ASCII, binäre Symbole, Trompeten-Signale, Flaggenschwenken |
Codierung mit Flaggen
Beispiel ![]()
Codierung mit Schall
Schallsignale ![]()
Datenverdichtung mittels Morse-Code
Diese Kompression ist verlustlos.
AB zu Morse ![]()
Codeliste ![]()



(Quicktimeplayer installieren!)
Download
BCD-Code (Ziffercodierung) 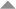
BCD-Code - AB | Aufgabe c) Stellen Sie die Dezimalzahl 4711 in BCD-Codierung dar! |
| Aufgabe d) Welche Besonderheit gibt es beim erweiterten gegenüber dem einfachen Gray-Code? |
| Aufgabe e) ASCII: Erstellen Sie für einen E-Mail-Link die Ausgabe in ASCII und fügen Sie dieses Tag in eine html-Seite zur Überprüfung ein! [Schütze deine E-Mail-Adresse mittels ASCII!] |
| Aufgabe f) Projekt: Erstellen Sie eine Homepage zu einem Ihrer Hobbys. Codieren Sie Ihre Mailadresse in ASCII. |
ISO 10646
Kompression mit Huffman-Codierung
Informationsgehalt, Entropie, mittl. Wortlänge, Redundanz ![]()
Zunächst einige Begriffe:
| Alphabet: | Einfachstes Alphabet: binäre Stellen - womit pro Stelle zwei Werte möglich sind, zum Beispiel 0 oder 1. Jede Stelle entspricht hier einer Informationsmenge von 1 Bit. Die Zeichen eines deutschen Textes können 26 unterschiedliche Werte (26 Buchstaben) annehmen. |
| Informationsgehalt p: | Der Informationsgehalt einer Nachricht hängt von der Wahrscheinlichkeit, mit der diese Nachricht auftritt, ab. |
| Entropie H: | Der (mittlere) Informationsgehalt einer Nachricht heißt Entropie der Informationsquelle. Sie ist maximal, wenn alle Nachrichten gleichwahrscheinlich sind. |
| mittl. Wortlänge L: | Summe der Produkte aus den einzelnen Codewortlängen li und den Auftrittswahrscheinlichkeiten pi der zugehörigen Zeichen des zu komprimierenden Textes. |
| Redundanz R: | Differenz aus mittlerer Wortlänge und Entropie: R = L - H. Mitunter gibt es Bereiche von Codes, die keine weitere Information enthalten (sie sind redundant), da die Information bereits in anderen Bereichen der Nachricht enthalten ist. Redundanz spielt eine Rolle, wenn fehlerhafte Codes korrigiert werden sollen.
Beispiel: weißer Schimmel ("doppelt gemoppelt") Der eigentliche Informationsgehalt hat sich trotz Weglassung der Vokale nicht geändert. |
Beispiel zur Datenverdichtung mittels Huffman-Codierung AB ![]()
![]()
Dazu nehmen wir den Text abrakadabra
Zuerst wird das Alphabet zu diesem Code bestimmt: arbkd - Aus diesen Buchstaben (und ihren Wiederholungen) besteht der zu codierende Text.
Für die Ermittlung des Codes mittels Code-Baumes wird die bottom-up-Methode verwendet:
1. Ordnen aller Zeichen nach ihren Auftrittswahrscheinlichkeiten: Das a tritt 5 mal auf, der Text umfasst 11 Zeichen, p beträgt also 5/11.
2. Eintragen der Zeichen und ihrer Auftrittswahrscheinlichkeiten in die Blätter
2. Zusammenfassung der beiden vaterlosen Zeichen mit den geringsten Wahrscheinlichkeiten
(Häufigkeiten) in einem Vater-Knoten, in dem die Wahrscheinlichkeiten der Söhne addiert werden
3. Fortführung des Verfahrens, stets die beiden Zeichen mit den geringsten
Wahrscheinlichkeiten zu einem weiteren Knoten zusammenführend,
bis es keinen vaterlosen Knoten mehr gibt
4. Den linken Kanten wird je eine 0, den rechten je eine 1 zugewiesen.
Das ist der Code:
a 0 (a kommt am häufigsten vor, erhält deshalb den kürzesten Code)
r 10
b 110
k 1110
d 1111
Bitfolge für abrakadabra: 01101001110011110110100
Das sind 23 Bit (anstatt 88 Bit wegen 11 Bytes bei ASCII-Verschlüsselung, 1 Byte = 8 Bit)
Kompression: Die Zeichenfolge wurde um ca. 73,1 % komprimiert.
An den zu übertragenden Code ist noch die Information, wie die einzelnen Zeichen codiert sind, anzuhängen. Deshalb wird die Zahl der Bits wieder etwas steigen.
Angewendet wird die Huffman-Codierung zum Beispiel beim FAX, bei MPEG, JPEG
Nachteile:
- Je größer das Alphabet ist, umso größer wird die Code-Tabelle.
- ungleichmäßige Bitrate und Decodierverzögerung wegen der unterschiedlichen Codewortlängen
- Wird ein Bit falsch erkannt, hat dies auch Auswirkungen auf die Bestimmung
der nachfolgenden Zeichen.
- Wahrscheinlichkeiten der Zeichen müssen bekannt sein oder sie müssen (aufwendig) abgeschätzt werden.
Bestimmung der Redundanz an obigem Beispiel
Auftrittswahrscheinlichkeit |
Informationsgehalt |
Code |
Codelänge |
Wortlänge |
||
| Alphabet | Anzahl des Auftretens des Zeichens im zu codierenden Text (inkl. Leerzeichen) geteilt durch Gesamtzahl der Zeichen des Textes |  Sie können aber auch einfach den Online-Rechner |
||||
pi |
hi |
li |
pi * li |
pi * hi |
||
| a | 5/11 = 0,454 |
1.139 |
0 |
1 |
0,454 |
0,517 |
| r | 2/11 = 0,181 |
2.466 |
10 |
2 |
0,362 |
0,446 |
| b | 2/11 = 0,181 |
2.466 |
110 |
3 |
0,543 |
0,446 |
| k | 1/11 = 0,091 |
3,458 |
1110 |
4 |
0,364 |
0,314 |
| d | 1/11 = 0,091 |
3,458 |
1111 |
4 |
0,364 |
0,314 |
| |
mittl. Wortlänge L = 2,087 Bit/Zeichen |
Entropie H = 2,037 Bit/Zeichen |
Redundanz: R = L - H = 2,087 Bit/Zeichen - 2,037 Bit/Zeichen = 0,05 Bit/Zeichen
Die Redundanz beträgt 0,05 Bit/Zeichen.
Fano-Bedingung: Achtung! Der Code muss eindeutig decodiert werden können.
-> Kein Code-Wort darf Anfangswort eines anderen Codewortes sein. Es iat also klar, wann ein Codewort zu Ende ist.
Anders gesagt: Es dürfen im Codebaum nur die Blätter, die Endknoten besetzt werden.
Solche Codes werden auch Präfixcodes genannt, und zwar in der Bedeutung, dass sie präfixfrei sind.
(Bei Block-Codes - Codes mit constanter Wortlänge - wird das Ende eines Code-Wortes durch Abzählen festgestellt.)
Aufgabe g) Untersuchen Sie, ob die folgenden Codes der Fano-Bedingung entsprechen:
|
| Aufgabe h) Schauen Sie sich die Applets und an und studieren Sie die PowerPoint:: 1. 2. 3. |
| Aufgabe j) Komprimieren Sie interaktiv PAPPERLAPAPP, KERNENERGIE, KRAMBAMBULI, SIMPLICIUS_SIMPLICISSIMUS ! Animal-Applet downloaden Anleitung zum Applet (Huffmann-Codierung): 1. Zip-Datei auf Rechner entpacken (Verzeichnis heißt Animal), Java muss installiert sein (ansonsten bei www.sun.de zu finden) 2. Auf animal.bat doppelklicken 3. Sprache auf Deutsch stellen 4. Drittes Icon oben links anklicken, Internet ist eingeschaltet 5. Bei Title "Huffman-Codierung" suchen, anklicken, dann unten auf Accept klicken 6. Vorführung durch Klick auf Play-Knopf unten |
| Aufgabe j) Huffman-Codierung: Kernenergie - Bestimmen Sie die Häufigkeit der einzelnen Buchstaben in diesem Wort! Erstellen Sie einen Binärbaum und schreiben Sie die Bitfolge auf! Berechnen Sie, um wie viel Prozent an Zeichen eingespart wurde, wenn zugrundegelegt wird, dass sonst für einen Buchstaben ein Byte (8 Bit also) notwendig sind! Vergleichen Sie das Ergebnis dann mit dem auf dem AB! |
| Aufgabe k) Huffman-Codierung: Kernenergie - Bestimmen Sie die Häufigkeit der einzelnen Buchstaben in diesem Wort! Erstellen Sie einen Binärbaum und schreiben Sie die Bitfolge auf! Berechnen Sie, um wie viel Prozent an Zeichen eingespart wurde, wenn zugrundegelegt wird, dass sonst für einen Buchstaben ein Byte (8 Bit also) notwendig sind! Vergleichen Sie das Ergebnis dann mit dem auf dem AB! |
Aufgabe l) Arbeiten Sie sich das AB |
| Aufgabe m) Wie groß ist der Informationsgehalt von 78 Tarotkarten? |
| Aufgabe n) Es gibt etwa 6000 japanische Kanji-Schriftzeichen. Welche Codegröße (Anahl der Bits) würde zur Codierung benötigt? |
Datenverdichtung mittels adaptiven Huffman-Codes ![]()
Hier wird ein dynamischer Code erstellt.
Im Laufe des Lesens werden die wahrscheinlichen Häufigkeiten abgeschätzt und damit stets neue Codewörter erstellt.
Beim Decodieren wird der Code-Baum ständig aktualisiert.
Vorteil des adapt. Codes: Zeichensatz muss nur einmal gelesen werden
Anwendung: in zip, gzip
Applet ![]()
Datenverdichtung mittels arithmetischer Codierung
Die zu codierenden Daten werden als rationale Zahl des Intervalls [0,1) codiert. Je länger die Nachricht, desto kürzer wird das Intervall., da die einzelnen zu übertragenden Zeichen entsprechend der Auftrittswahrscheinlichkeit verkleinern. Die weniger vorkommenden Symbole verringern die Größe des Intervalls mehr als die häufiger vorkommenden.
Die maximale Redundanz pro Nachricht ist <1 Bit.
Diese Kompression ist verlustlos.
| 1. Beginne mit einer Definition des aktuellen offenen Intervalls [0,1) (jede Zahl zw. 0 und 1, außer 1 selbst) | |||
| 2. Wende für jedes Symbol der Eingabe die folgenden Schritte an: | |||
| 1. Teile das aktuelle Intervall in Teilintervalle, die proportional zu den Wahrscheinlichkeiten der Eingabesymbole sind | |||
| 2. Selektiere das Teilintervall des Eingabesymbols und definiere es als das aktuelle Intervall | |||
| 3. Wenn die Codierung abgeschlossen ist, finde eine Zahl innerhalb des letzten Intervalls welches die dieses Teilintervall exakt beschreibt | |||
| 4. Schreibe die ermittelte Zahl in eine Datei. | |||
Applet ![]()
Weiterführende Informationen ![]()
Datenverdichtung mit dem Lempel-Ziv-Welch Code ![]()
![]()
- verlustlos, adaptiv
- keine Info über Wahrscheinlichkeitsverteilung der Zeichen des Ausgangszeichensatzes
erforderlich
Im LZW- Verfahren werden redundante Zeichenketten durch kürzere Codes ersetzt, wobei keine Informationen zur Dekomprimierung abgespeichert oder übertragen zu werden brauchen. Für das Dekomprimieren wird im Laufe der Dekodierung ein Wörterbuch (Tabelle mit Kompressionscodes) aus dem Datenstrom erstellt.
Beispiel
ZZLWLWLLWZLWWLWZZLWLWLWLWWWZZWLWL
1. Möglichkeit:
ZZ LWLW L LWZ LW W LWZ Z LWLW LWLW WW ZZ W LW L
Komprimiert:
1 2 L 3 4 W 3 Z 2 2 WW 1 W 4 L
Wörterbuch dazu:
[1=ZZ, 2=LWLW, 3=LWZ, 4=LW]
2. Möglichkeit:
ZZLWLWL LW Z LW W LW ZZLWLWL LW LW WWZZW LW L
Komprimiert:
1 2 Z 2 W 2 1 2 2 WWZZW 2 L
Wörterbuch dazu:
[1=ZZLWLWL, 2=LW] (weniger Einträge -> weniger Speicherbedarf als bei der 1. Möglichkeit)
Tutorial ![]()
Anwendung: bei Daten mit häufig wiederholten Symbolen, GIF, TIF, einige Komprimierungstools
| Aufgabe o) Applet |
Animation 1 ![]()
 Fraktale Bildkompression
Fraktale Bildkompression
Ausgangsvorstellung: In der Natur kommen häufig gebrochene Dimensionen vor, zu Beispiel in Form einer Küstenlinie oder eines Gebirgszuges oder bei der Baumrinde. Beispiele für Fraktale:
Fraktale Plantagen
Fraktal-Generator WinCIG
Prinzip bei der fraktalen Bildkompression:
Das Bild wird auf Ähnlichkeiten hin untersucht, welche durch Verkleinerungen und Drehungen ineinander übergehen. Für solche Selbstähnlichkeiten werden an den Empfänger nur entsprechende Formeln (Linsenparameter) gesendet. Beispiel: Sierpinski-Dreieck

Vorteile:
- hohe Kompressionsrate
- Vergrößerung des Bildes ohne große gefahr der Pixelierung
Nachteil:
Komprimierung erfordert (im Gegensatz zur Dekomprimierung) relativ viel Zeit.
Wavelet-Kompression
Diese Kompression ist verlustbehaftet.Demo 1
Erläuterungen
Beispiele:
SPHIT, EZW (Videokompression)
Diese Kompression ist verlustbehaftet.
Anwendung: MPEG-1, MPEG-2, MPEG-4
Erläuterung: ![]()
ASPEC (Audiokompression)
JPEG, JPEG2000 (Bildkompression)
Kompression von Bildern zugunsten der Dateigröße Anwendung: JPG (häufigstes Format bei digitalen Fotoapparaten)
Erläuterung:
Aufgabe q) Verschaffen Sie sich einen Überblick über verlustfreie Komprimierung und verlusthafte K.!
Nutzen Sie dazu auch diesen Text ! Beachten Sie vor allem, wie sich verlusthafte Komprimierung bei Musik- und Bilddateien bemerkbar macht! Erstellen Sie ein Quiz dazu!
Aufgabe r) Ordnen Sie die folgenden Verfahren der verlustfreien bzw. der verlustbehafteten Kompression zu! ZIP, MP3, JPG, Dolby Digital, GIF, RAR, MPEG-2, ARJ, DivX
Aufgabe s) Erstellen Sie mit Hilfe eines Grafikprogramms von einem unkomprimierten Ausgangsbild mehrere JPG-Kopien mit unterschiedlicher Datenkompression! Welcher Zusammenhang ergibt sich zwischen Dateigröße und Qualität?
Oder: Erstellen Sie mit Hilfe eines Audioprogramms von einem unkomprimierten Ausgangssound mehrere MP3-Kopien mit unterschiedlicher Datenkompression! Welcher Zusammenhang besteht zwischen Dateigröße und Qualität?
Aufgabe t) Vergleichen Sie Vektor- und Pixelgrafiken! Nennen Sie Vor- und Nachteile beider Grafikverfahren sowie typische Anwendungsbereiche!